



By Pradipta Deb
The Messaging, Malware, Mobile Anti-Abuse Working Group (M3AAWG) invited Pradipta Deb, to provide a brief overview of his presentation on Artificial Intelligence and Large Language Models (LLMs) during training sessions he delivered at M3AAWG's 60th General Meeting in San Francisco, California, this past February.
Deb discusses classical language modeling and the emergence of LLMs. Classical language modeling, such as n-gram models and feed-forward neural networks, had simplicity and efficiency but lacked generalization and context. The Transformer architecture, introduced in 2017, revolutionized language modeling by effectively capturing long-range relationships through self-attention mechanisms. Transformers are parallelizable, scalable, and have achieved state-of-the-art performance in Natural Language Processing (NLP) tasks.
Introduction to Classical Language Modeling:
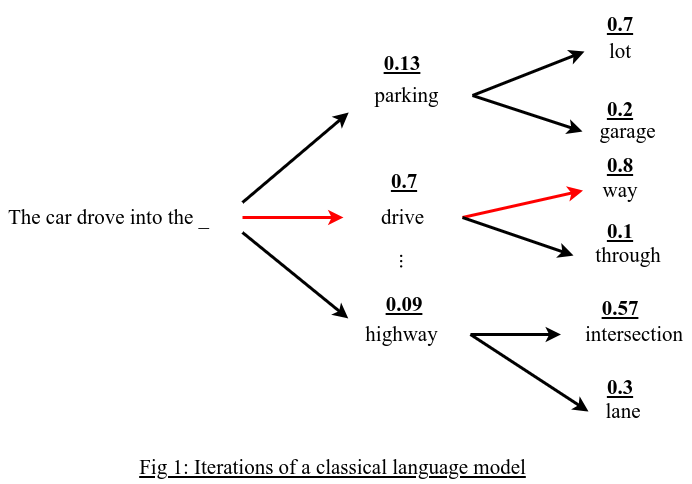
One of the core tasks of Natural Language Processing (NLP) is language modeling, which estimates the likelihood of a word or token sequence in a particular context. Speech recognition, machine translation, text production, and question answering are just a few of its many uses. The n-gram model, which counted the frequency of word sequences in a corpus of text, served as the foundation for early language models. The primary benefits exhibited by conventional language modeling methods, like feed-forward neural networks and n-gram models, were their simplicity and efficiency. They were appropriate for real-time applications since they could be swiftly trained and assessed. They did, however, also have several serious shortcomings, such as poor generalization, sparse data, and limited context.
Evaluation of Transformers and Large Language Models
The Transformer Architecture:
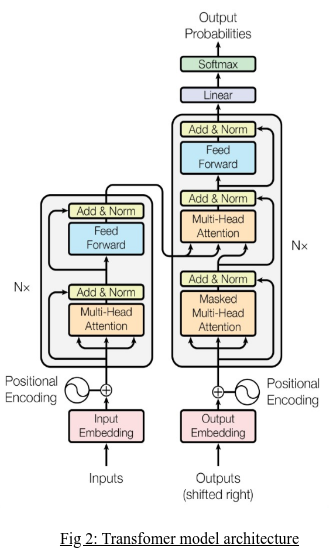
The Transformer architecture's parallelizability is one of its main benefits. Transformers are more scalable and economical because they can process input sequences in parallel, in contrast to RNNs, which process sequences sequentially.
Transformers have been trained on massive volumes of data and have achieved state-of-the-art performance on an extensive variety of tasks related to natural language processing thanks to this parallelization and the self-attention mechanism. The development of more sophisticated architectures, like the Reformer and the Longformer, which attempt to address the quadratic computational complexity of the self-attention mechanism and enable even more efficient processing of longer sequences, has also been made possible by the success of the Transformer architecture.
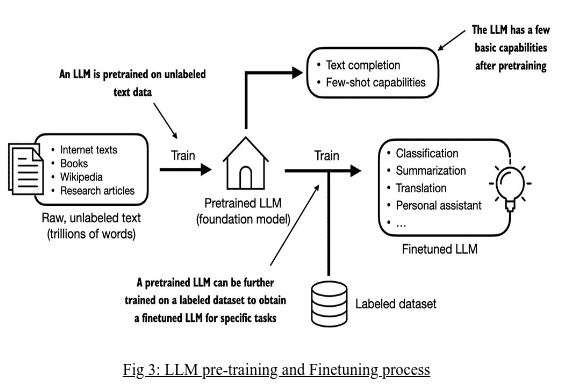
The Emergence of Large Language Models (LLMs)
Large Language Models (LLMs) have been developed using self-supervised learning techniques, enhancing the Transformer framework by training on extensive text data. These models, pre-trained on vast text corpora, acquire general knowledge and understand complex linguistic representations. LLMs like OpenAI's GPT, Google's BERT, and Facebook's RoBERTa have demonstrated exceptional performance on various NLP tasks, setting new benchmarks. They are trained on large datasets, often containing billions of words from diverse sources such as novels, websites, and scholarly articles.
The key advantage of LLMs is their ability to leverage transfer learning. They gain a deep understanding of language through extensive pre-training and can be fine-tuned for specific tasks or domains using relatively small task-specific datasets. This approach has proven successful, enabling LLMs to achieve state-of-the-art performance in applications like question answering, machine translation, summarization, and text generation.
Model Fine-tuning - Next Stage of Training
While LLMs are pre-trained on a large volume of text data, they can be fine-tuned for specific applications or domains to increase performance. This procedure entails updating the model's parameters with a smaller, task-specific dataset, allowing the model to adapt to the specific needs of the target task. Fine-tuning has proven to be a viable strategy, allowing LLMs to reach cutting-edge performance on a variety of downstream tasks with minimal extra training data.
Limitations of Large Language Models
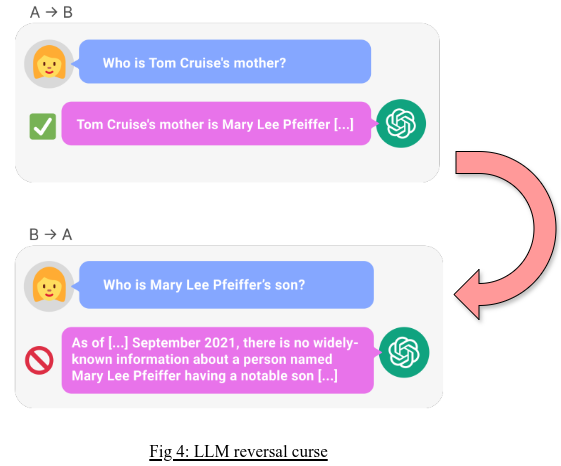
Regardless of their great capacities, LLMs have some limits. They frequently lack a solid grasp of the world, resulting in illogical, uninformative, or biased responses in some situations. Furthermore, training and deploying LLMs involves enormous computer resources, making them both costly and energy-intensive. The quality and diversity of training data can have a significant impact on the model's capabilities and biases. Furthermore, LLMs may produce damaging or biased information, posing ethical questions about their deployment and use.
Ongoing Evaluation and Improvements
As Large Language Models (LLMs) become more intricate, research focuses on enhancing their performance and capabilities. One key area is the development of multimodal LLMs that process and generate data from various modalities like text, images, and audio, aiming for a comprehensive understanding and generation of information. Additionally, efforts are being made to address LLMs' drawbacks, such as producing harmful or biased content. Techniques like constitutional AI and instruction-tuning are being explored to create LLMs that adhere to specific rules during training and generation, fostering safer and more ethical AI systems.
As language modeling progresses, the evaluation of Transformers and LLMs will be crucial for future advancements and ensuring these robust models are developed and used responsibly.
Pradipta Deb is a Research Engineer for the Hornet Security Research Team in Hem, France. He has several years of expertise in machine/Deep learning and is currently working on content understanding in the realm of email and Natural Language Processing (NLP) with a focus on email security. He received a Masters of Science in Computer Science from Saarland University in Germany.
References:
- The Animated Transformer
- LLM Foundations - The Full Stack
- [1706.03762] Attention Is All You Need
- [2309.12288] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++
- [2212.09720] The case for 4-bit precision: k-bit Inference Scaling Laws
- Understanding Large Language Models